首页
好价
精选好价
全部好价
优惠券
白菜
社区
好文
资讯
众测
笔记
海淘
海淘导航
淘遍世界
攻略文章
百科
商品百科
品牌导航
商家导航
更多
值友福利
金融
汽车
旅游
品类导航
专题汇总
招聘专区
集团官网
商业合作
爆料投稿
好价爆料
写篇文章
视频上传
提报百科
创作活动
条新消息
条新评论
登录
注册
个人中心
我的关注
我的文章
我的爆料
我的笔记
我的视频
我的百科
我的评论
我的众测
我的消息
我的收藏
退出登录
个人主页
我是中国的
+
关注
算法工程师
数码领域作者
注册12周年
・
签到3055天
IP属地:上海
芝麻信用评估
授权
后可查看具体分数
芝麻信用评分是合法独立的信用评估及信用管理机构,授权后得到分数越高,代表信用越好
首页
爆料 5236
文章 290
笔记 636
视频 3
评论 443
cvpr ai顶会
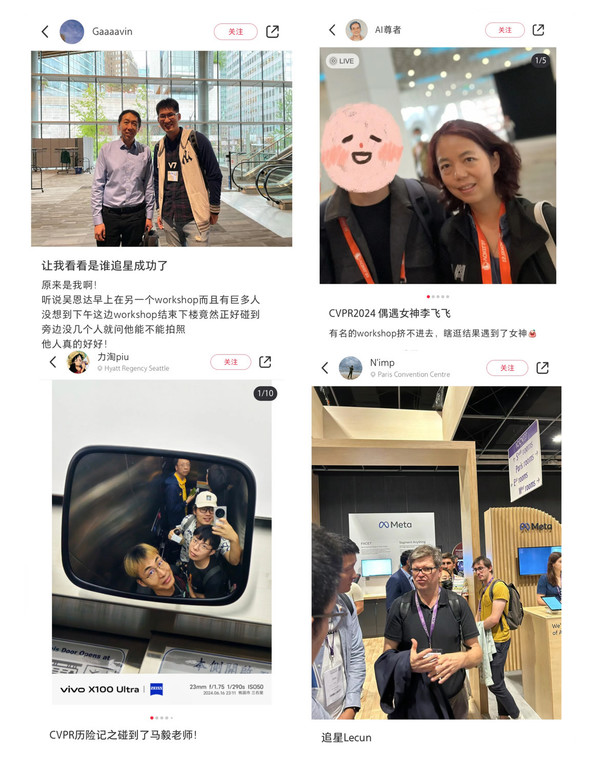
6月17号,美国西雅图会议中心,全球计算机视觉届三大顶会之一的CVPR 2024来了。大会持续一周,目前参加下来最直观的感受就是热,太热:巨大而火热的信息量,处处爆满的参会人群。可以说从走进主会场那一刻起,“人山人海”这个词就被具象化了。而CVPR官方也兴奋的宣布:今年的大会破了参会记录,有超过1.2万人从全世界涌来,人挤人的来参加一个过往只是“冷门领域”的AI学术会议。图: Junwei Zhang经过前两天密集而硬核的workshop和tutorial,今早8点半,最受关注的开幕颁奖环节终于在Summit Flex Hall揭晓。最佳论文开奖,全与生成式AI有关今年CVPR论文提交数量来到破纪录的11532篇,被接收的2719篇中有324篇被选为highlights,90篇较优秀的论文进入oral,oral里再选出24篇顶尖玩家杀进决赛圈终极对决。单看大屏幕的数据,现场悬念氛围就已经拉满,所有人都按捺不住紧张和兴奋。图:CVPR最终,大会宣布本次总共十篇论文胜出。包括2篇最佳论文奖(Best Paper)和2篇最佳学生论文奖(Best Student Paper),以及代表亚军级别的2篇最佳论文次优奖(Best Paper Runner Ups)和4篇最佳学生论文次优奖(Best Student Paper Runner Ups)。“Generative”,这是今年全球最大计算机视觉会议发布最佳论文时,屏幕上出现的第一个单词。毫不意外。两篇最佳论文分别花落谷歌研究院的「Generative Image Dynamics」和加州大学圣迭戈分校的「Rich Human Feedback for Text-to-Image Generation」。两篇都与图像生成和模型有关,不得不说现在AIGC领域真得太火。图:CVPR谷歌这篇是通过从自然运动(比如花朵在风中摇晃)的真实视频里学习运动规律,开发出一个能基于任何静止图像预测并合成逼真运动效果的AI模型,简言之就是让照片"动"起来。UCSD的论文从数据入手,先对人工标注的反馈数据进行细致收集,再由此训练一个AI模型来评估和改进图像质量,令生成的图像更贴合文字描述——后来得知,这是该作者团队的第一篇CVPR论文,而且主要成员都是华人。初次闯关就拔得头筹,确实让人刮目相看。两篇最佳学生论文奖则被德国图宾根大学的「Mip-Splatting: Alias-free 3D Gaussian Splatting 」和俄亥俄州立大学的「BioCLIP: A Vision Foundation Model for the Tree of Life」团队捧走。前者提出了一种新的3D建模和滤波方法,能解决不同缩放下生成3D图像可能存在的瑕疵和失真问题。后者整理出目前规模最大、生物多样性最丰富的机器学习图像数据集,基于此开发的BioCLIP模型专门从图像识别中提取生物学知识。此前麻省理工学院呼声很高的论文「pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction」拿到了最佳论文次优奖,也算没空手而归。另一家Best Paper Runner Ups得主是来自国内的北京大学团队。他们在「EventPS: Real-Time Photometric Stereo Using an Event Camera」论文中提出一种事件相机只需要在光线变化时捕捉信息,就能快速精确估计出物体表面朝向,而无需拍摄多张照片的新方法,非常适合需要快速响应的实时应用场景。当北大的名字出现在舞台大屏幕上时,现场好多华人观众们都禁不住振奋鼓掌,自己人拿奖,内心还是很激动的。图:X.com | @RainbowYuhui最后,四篇最佳学生论文Runner Ups也相继出炉。北京大学与华为诺亚方舟实验室合著的「Image Processing GNN: Breaking Rigidity in Super-Resolution」再次榜上有名。另外三家是俄勒冈州立大学、波恩大学、卡内基梅隆大学。研究方向涵盖了Transformer和卷积神经网络、3D形状匹配、随机几何建模以及图神经网络。图:CVPR逛Poster Session如赶集,作者“连讲4小时没顾上喝水”今天起,包括这些获奖论文在内的90篇 oral 都被安排进各分会场开启口头报告。除了Oral Session这种PPT展示的传统演讲形式外,还有2305篇论文被分配到了Poster Session,即海报展示环节。在硅谷大厂发布会中不常见的Poster Session,实则是国际大型学术会议的重要组成部分。研究人员们把自己的论文制作成图文并茂的学术海报,张贴在固定区域展示研究成果。好处是不受时间限制,可以全天候驻场,跟参会者们面对面讨论。尤其适合新入学术圈的研究生和年轻学者增加曝光机会,也是结识同行、交流经验的重要social场合。就像你参加过的任何一场贸易交流销售大会一样,这里的人们也在寻找“推销”自己和自己的研究的机会,无论是为自己寻找好的工作机会还是吸引来趣味相投的潜在合作者,Poster环节都热闹而生机勃勃。Poster Session的热闹程度不亚于Oral房间,逛下来也是摩肩接踵的人挤人。大会休息间隙几乎整个区域每张海报前都围了人问问题。有位作者就笑称,给论文海报站台比做演讲累多了,“因为oral再重要也是只讲一遍,可poster来人就要重新讲一遍,问题也可能回答好几轮。”海报区犹如美院毕设,Highlight论文前人群已挤爆。图:X.com | @eshedob当然大家都乐在其中。几位国内来的年轻学者们特别提到,虽然今天中美之间在AI、计算机等领域并不完全透明,但在CVPR现场遇到的每个人、不论国籍都十分乐于交流,拥抱学术开源。在这样的背景下,语言也不再是壁垒,“开始还有点不自信,但真聊起来发现,依靠自己平时专业积累完全可以输出想法,交换观点”,“本来以为说一会儿就完事,结果连讲4个小时没顾上喝水。”如果说产业界还有些浮躁、焦虑或芥蒂,学术界则更偏向于敞开心胸,共享知识进步。不过有意思的是,也有些业界大哥略显内敛。比如特斯拉、Waymo、Zoox这次提交的论文都很少,不知是自动驾驶行业今年挑战巨大成果难出,还是竞争激烈有意藏一手。毕竟这条赛道的商业化之路不容易,维护技术护城河也是情理之中。变化中的CVPR,AI风暴眼中FOMO的人们想来从上周末开始,就陆续听闻同行旧友们从世界各地飞抵西雅图塔科马机场。会程中,市中心酒店、餐厅、街边聚集每天都有自带学术气息的人群聚集,其中很多朝气蓬勃的华人面孔,成了这座尚未完全解锁夏天的城市一道热闹的风景线。生成式AI全面嵌入生产生活,也让更多人记住了CVPR这个历史悠久、硬核而神秘的学术顶会名字。偌大几层楼的会场里,前两天已跑断腿:100多场密集排满的工作坊和教程,主题横跨生成模型、人类理解、医疗视觉、3D/4D建模,神经渲染、多模态、开放世界学习、通用AI代理….好多场次是从早上8点一直进行到下午6点。但即便你一早到场,也未必能挤得进去:几乎所有workshop的房间都很快满员。特别是那些AI相关的火热领域,或是Meta、OpenAI、LumaAI这些明星公司,瞬间就被围得水泄不通。人群中、空气里,弥漫的都是求知欲、交流欲和强烈的FOMO情绪。主办方为了人均有座位控制人数,满员就不再放人。想听只得在门口等,出一进一。于是许多门前都排起了望眼欲穿、等待补位的长队。图:小红书分享勉强挤进「AI for Content Creation」房间。内容生成本就堪称最热门主题之一,这场又集合了OpenAI Sora团队研究主管Tim Brooks, 南洋理工教授Ziwei Liu等业界大牛。作为破了记录第一次有1.2万人涌入的学术大会,CVPR的主办方显然一开始也有点招架不住。起初他们拒绝让更多人进入没有座位的worksho讲厅,后来随着社交媒体上的抱怨声多了,也做了调整。主办方终于多放了些观众进来,席地而坐或站在过道听。图:Junwei Zhang午餐时间来到干饭现场,不小心再次接受了洗礼:一屋子肤色各异的研究员们,愣是吃出了气势磅礴的军训的气势。嗯,学术顶会是这样的~
+1
0
0
0
2024-06-21
极氪已经卷得很成功了,还要领克卷吗?
家庭中的小故事,和我们商业战场是一样的。领克Z10,官方供图2024年6月12日,领克品牌首款纯电车型领克Z10瑞典斯德哥尔摩全球首发,领克Z10不光基于吉利SEA浩瀚架构,也用上了金砖电池,它还全球首发电磁悬挂技术,用上了FlymeAuto智能座舱、吉利自研E05芯片等。产品一出来就收获了巨大的关注,以及疑问。虽然和大哥极氪001在一些方案上做了区分,但总的来说,算是包括了极氪在内的,吉利集团技术的全力加持。因为系出同门,和极氪在外观设计上也略有相似,但领克还是从设计源头上强调了不同。极氪001诞生于2020年领克发布的ZERO Concept概念车,而领克Z10可以看作是领克The Next Day概念车的量产形态,两者有所区隔。但有人还是要问了,三年前诞生于领克体系下的极氪,主攻高端纯电,领克甚至为此还让出了纯电这条赛道。极氪这两年也已经拿到了不错的成绩,尤其是在如今已经如此惨烈的市场环境下,那为什么领克还要出来卷,一卷就是一个先卷兄弟?吉利汽车集团高级副总裁、领克汽车销售公司总经理林杰有不同看法,他认为两者存在根本上的不同。相同的是两者都有着集团的技术资源——都出自SEA浩瀚架构,有相同的安全和性能基因。不同的是品牌定位——领克定位全球新能源高端品牌,愿景是“持续改变移动出行,让人们更热爱出行”;极氪定位新时代豪华科技品牌,使命是“共创极致体验的出行生活”。而用户人群上——领克品牌的人群是个性、开放、互联的年轻态都市人群,他们见解独到,敢于探索;极氪品牌的人群是生活的极客,对先锋科技保持狂热好奇。说实话,这算是非常官方的回复。我是没太听出来这两类用户究竟有什么特别大的区别。吉利汽车集团CEO淦家阅则给出了一个基于用户,以及品牌增量的回复。他首先强调Z10对领克来说特别重要。一直以来,领克以潮流、运动、个性的品牌调性,深受客户认同。领克做过调研,有60%的领克用户很希望领克出纯电产品,满足新能源市场快速变化的需求。“所以我们顺应市场变化,对领克品牌来讲,Z10也丰富了我们的产品线,同时丰富了用户的选择。”对于领克来看,纯电是增量市场,这倒是不能否认的,能争取到这样的资源确实有机会丰富品牌的销量。但领克和极氪之间的定位,还是有点说不清。两家品牌虽然强调了品牌上的独特性。但对于用户来说——尤其是极氪的用户,早期选择极氪,大部分是因为喜欢领克品牌又想买纯电,由于当时领克没有纯电产品,所以最终选择了极氪。而现在被放到一起讨论做品牌的区分,最大的可能是,在集团层面对两个品牌进行了重新梳理。实际上,从这两年极氪的动作来看,一直是在“向上走”的过程。极氪,图片引用自网络极氪001是非常成功的,定义了豪华猎装品类的产品,极氪007是一个非常个性的年轻化小车,成为了如今极氪的双拳产品之一,“宝宝巴士”极氪MIX更加强调独立的设计风格,极氪009光辉版以及刚刚成立的光辉事业部,使得极氪变得越来越像一个“豪华品牌”,也更独立。但极氪X这类小众的产品却没能大获成功。刚需型市场更在意空间、实用属性,而极氪X实际上希望在20万级别甚至以上提供一个轻奢型的产品——这是产品定位和功能上的错配。极氪X取消20万以下的产品矩阵也验证了:很有可能,未来极氪将专注于高端豪华,而领克有机会承接下相对亲民的纯电市场。最终形成高端豪华+相对亲民的布局。如果是这样一个搭配的话,那也意味着吉利在集团层面重新分配一些资源。接下来,就看领克Z10卷得怎么样,能不能美美与共了。
+1
0
0
2
2024-06-20
同为打工人,马斯克薪酬560亿元
特斯拉CEO马斯克560亿美元天价薪酬,最终在2024股东大会上通过表决,马斯克成为了汽车圈薪酬最高的打工人。这份天价薪酬的制定还要追溯到2018年。当时,特斯拉刚刚完成一年10万辆的交付,全年亏损22亿美元,面临着大规模交付、如何盈利等一系列难题。但与此同时,马斯克也刚刚完成在2012年制定的第一个十年股权激励计划——一项将市值增长指标、生产经营指标逐级划分的严苛业绩目标,完成后马斯克会获得相应期权,而不是薪资或者奖金。马斯克在2017年就完成了市值目标,经营目标也达到了8级,于是,第二个更大胆的十年股权激励计划诞生了。这份股权激励计划同样将市值增长目标以500亿美元为一级,设置了12级目标,其中第12级需要特斯拉的市值达到6500亿美元,每达到1个里程碑,马斯克就可获得1%的特斯拉股份。生产经营目标则包括16个指标(8个跟收入相关,8个跟EBITD,也就是所得税前利润相关),马斯克可以从里面选12个,都完成了就算达成一对小目标。实现每档目标后,马斯克可以选择以每股350.02美元的价格购买169万股特斯拉股票,所有目标实现后,马斯克将获得总额超过500亿美元的股票奖励,同时这些期权只有在马斯克持有至少五年的情况下才能完全兑现。截至2023年年底,特斯拉市值约为7900亿美元。同时,在2023年,特斯拉交付了180万辆新车,营收达到968亿美元,净利润150亿美元。图源:特斯拉但是,这样的成绩依然没有能够让马斯克顺利获得天价薪酬。马斯克和特斯拉的多位董事被一个仅仅持有9股特斯拉股票的小股东起诉了,这位股东认为薪酬方案不公平。毕竟,美国汽车行业来看,通用汽车首席执行官玛丽•博拉(Mary Barra)2023年的薪酬总额2780万美元,在欧洲,Stellantis首席执行官唐唯实的2023年薪资3650万欧元。而马斯克的薪酬,可以称为是汽车圈最高薪酬了。今年年初,特拉华州法官Kathaleen St. Jude McCormick裁定薪酬方案无效,也让马斯克最终能否获得期权奖励多了很多变数。不过,马斯克这项涉及560亿美元的薪酬方案,最终还是通过股东重新投票的方式,以73%的赞成票通过。这足以看出,马斯克在特斯拉股东中的认可度。不过在此之前,特斯拉内部也刚刚经历一场巨变。4月末,马斯克前脚到访中国推动FSD在中国落地事宜,紧接着5月,特斯拉全球裁员20%,马斯克更是裁掉了整个超充团队,这也被视为马斯克对特斯拉进行战略调整的信号之一。图源:网络随着天价薪酬尘埃落定,在此次股东大会上,马斯克还雄心勃勃地宣布了接下来特斯拉的发展重点。关于传言被砍掉的超充网络,马斯克称,特斯拉今年将投入5亿美元,用于进一步扩大和完善超级充电站网络;在美国本土热度颇高的Cybertruck,马斯克也“剧透”,后续特可能会为中国和欧盟制造特供版Cybertruck。马斯克还透露,上周他正式批准了特斯拉电动卡车Semi的量产计划。他表示,特斯拉Semi将为企业带来实质性的价值,因为它能为运营商节省大量成本,从而提高运营效率。关于4680电池,马斯克称,特斯拉4680电池的成本高于供应商,但预计到今年年底将实现成本平衡。关于FSD:目前已经做到几乎完全消除静态物体碰撞;特斯拉正在试图使用在阴影模式下加载模型的方式解决AI模型测试问题,目前已在美国确定数千个复杂十字路口用于测试。图源:网络马斯克还提到了机器人出租车模式,这一模式中,部分车辆将由特斯拉直接拥有并运营,而另一部分则将归属于特斯拉客户。马斯克称,这一策略赋予了特斯拉车主对其车辆使用的完全掌控权,让他们能够灵活决定何时将爱车投入到特斯拉的机器人出租车网络中,以实现价值的最大化。图源:特斯拉官方在股东大会问答环节,有股东提问,如果没有马斯克引领,特斯拉的前景会怎样?马斯克表示,自己是特斯拉美好未来的助推器,对于一家公司来说,最重要的不是创新本身而是创新速度。而马斯克之于特斯拉最大的贡献,就是推动了公司的创新步伐。
+1
0
0
0
2024-06-15
广汽大裁员,好日子到头了,广本裁员千人
广汽要被时代淘汰了,日系合资已经毫无竞争力。广汽还想着靠丰田坑蒙拐骗能收割国人的血汗钱呢?2008年左右广汽的车加价提车的时候,也没见消费者说呼吁国家制止加价行为啊!图源:评论截图言语中的,都是对过去广汽依靠合资品牌躺赢时代的不满。而事实上,今年前五月,广汽集团也的确经历着惨烈的下滑。今年1-5月,原有的市场主力合资板块中,广汽本田、广汽丰田今年前五月累计下滑分别为24.3%、27.26%,在新能源市场一向强劲的广汽埃安,今年前五月的下滑则达到38.71%,唯一增长的只有广汽乘用车,前五月累计增长6.24%。整个前5月,广汽集团比去年同期的销量少了22.7万辆。图源:产销快讯截图与此同时,曾庆洪还提到,今年广汽集团经历了裁员。销量下滑加上裁员,足以把广汽集团推向风口浪尖。广汽集团面对的这场舆论风波,起因就是曾庆洪在行业发言中吐槽如今汽车行业内卷过度,网友认为是广汽卷不动,呼吁国家干预,这种表现太过巨婴,而广汽集团也不得以重新梳理了曾庆洪的发言,将其发言的核心总结为广汽集团不反对、也不怕“卷”,来反对汹涌的舆论。在最近举行的中国汽车重庆论坛上,汇集了包括比亚迪、吉利、长安、广汽、理想、蔚来在内的不少车企掌门人,这场论坛上,大佬们都不约而同谈到了一个话题——要不要卷,如何应对内卷。大佬们输出的内容却多少有点“针锋相对”。比如,长安汽车董事长朱华荣前脚刚讲完,内卷本身意味着对卓越的追求,这种竞争将提升中国品牌的高度,并最大化用户利益。广汽集团董事长曾庆洪紧接着就开始“泼冷水”:“这样卷下去不是办法。企业的目的是什么?是盈利。而盈利又是为了什么,是为社会做贡献,包括交税和提供就业岗位。”之后,比亚迪董事长王传福,也带来了满满的正能量:王传福把卷视为竞争,王传福说,“市场经济的核心是什么?就是过剩。只有过剩才有竞争,竞争才能产生繁荣,这是一个自然规律,不必焦虑、所有的企业家要拥抱、参与这种卷,拥抱这种竞争,在竞争中出海。”言语中,都是车市巨头的自信。随后,吉利控股集团董事长李书福也谈到了很多车市内卷的弊端:比如,对于中国汽车市场如今的内卷程度,李书福提到,“中国汽车工业的内卷程度全球第一,价格战一浪高于一浪,也是举世无双,这种现象既是好事也是坏事。”同时,李书福也从两个层面指出了内卷带来的正面影响和负面影响。他说,如果市场化水平高,法律健全,执法严格,透明公平竞争这就是好事;反之,就是坏事。无穷无尽的内卷,简单粗暴的价格战,其结果就是偷工减料、造假售假、不合规的无序竞争。图源:官方虽然,李书福和曾庆洪都指出了内卷对于行业的危害,但是炮火全都落在了广汽上。其实,曾庆洪只是说了不少实在话。曾庆洪发言的潜台词是,汽车行业如今的内卷是不正常的,也为产业发展带来了负面影响。但是,这也被很多外界声音质疑,这是因为广汽卷不动了,没有能力适应当下的竞争。刚刚上市的昊铂GT全球版核心技术主打无图智驾全球通 图源:网络事实上,相比于自主军团们,广汽集团面临着复杂的品牌结构。广汽集团不能以打倒合资的目标来发展新能源,也不能高喊杀死燃油车,全力发展电动化技术,它的转型路径更为复杂。广汽集团怎么做,其实是没有参考答案的。曾庆洪在发言中提到了“油电同权”,这一市场困境不仅仅是广汽一家的问题,其实也是中国汽车市场从合资主导到自主变强阶段,几大汽车集团都在面临的问题。曾庆洪还举了丰田汽车的例子。他说,2023年国内主要18家上市车企中,有12家实现盈利,但这12家中国车企2023年的净利润加起来也没有超过900亿。丰田的净利润是12家中国车企加起来的2倍多。曾庆洪是想指出,很多中国车企在以自己亏损的代价血拼价格战,而跨国集团们依然在保持着稳定甚至是超预期增长的盈利水平。当跨国车企依靠全球市场份额躺赢时,中国车企却在价格战中头破血流。而这个阶段,无论主动或被动,都没有逃避的空间。最近宝马电动车近乎五折,一汽-大众启动官降,在中国汽车市场,已经没有一个品牌能够有恃无恐的冷眼旁观这场竞争。风口浪尖的广汽集团,很长一段时间里产销规模在中国汽车产业位居前五。今年的持续下滑,也让广汽集团在5月的集团排名中跌出前五。5月有媒体报道,广汽本田启动大规模裁员 图源:微博曾庆洪其实是大集团中少有敢说大实话的掌门人,比如过去曾庆洪吐槽,“电池太贵了,车企都在为宁德时代打工”,此次发言中提到的“水军多到不可思议”,指出了不同阶段不少行业激烈竞争的现状。虽然整个行业都在高喊坚持长期主义,开辟全球市场,保持技术护城河,但事实却是,激烈的竞争必然导致了产业结构中的一些动作变形,这些问题,同样应该被关注。但是眼下,广汽似乎并不应该提出问题的角色,而是展示出以凭自己本事应付复杂局面的能力。毕竟大家已经听腻了被卷,整个行业都期待大洗牌过后重新焕发出生命力。广汽需要一个逆袭的新故事了
+1
0
0
0
2024-06-13
海尔波轮10kg全自动洗衣机
海尔拿10公斤洗衣机正好爸妈。家在装修这个品牌已经看了很久,这个款式也很喜欢波轮的,就是比滚筒的方便,不需要弯腰,所以说第一时间就考虑了这个品牌和这个洗衣。。拿到手之后掂量了一下,非常的有重量感,而且颜色也很好看,跟家里的装修非常的。搭配,值得信赖,好东西大家要一起买,所以说强烈推荐给大家为民族品牌崛起而骄傲,国产加油。
+1
1
1
0
2024-06-12
松下洗衣机
松下洗衣机,趁这次618搞活动买了一台,之前的旧洗衣机也是松下的,用了差不多六七年了,感觉有点脏,所以说想要趁活动搞一个新的,拿到手之后还是很有分量,颜值也非常的高,试了一下又快洗各种各样的洗涤程序,可以经过选择非常的方便,而且大品牌值得信赖,我想一份价钱一份货,东芝的产品品牌力还是不错的,强烈推荐给大家,希望大家也用得好用的,放心。
+1
1
0
1
2024-06-11
真维斯,你值得拥有
618买了一件真维斯t。真维斯品牌的T恤衫在消费者中享有较高的声誉,得益于其合理的价格和良好的材质。下面将详细介绍真维斯T恤的特点:1. 价格优势: - 真维斯T恤的价格亲民,相较于市场上许多同类品牌,如迪卡侬等,真维斯提供了更为实惠的选择,让消费者能以较低的价格享受到质量可靠的产品[^2^]。 - 在众多购物平台和实体店中,经常可以见到真维斯T恤的各种优惠活动,进一步增加了其性价比,使得广大消费者能够轻松拥有。2. 材质舒适: - 真维斯T恤多采用全棉或含有高比例棉质材料,保证了穿着的舒适度,并有利于吸汗透气,适合夏季穿着[^2^]。 - 全棉材质也确保了衣服的柔软性和对皮肤的友好性,即使是敏感肌肤的消费者也可放心穿着。3. 设计简洁: - 真维斯的T恤设计简约而不简单,无论是纯色还是带有印花图案的款式,都能轻松满足不同消费者的个性化需求[^2^]。 - 真维斯的尺码设计较为准确,尽管有些消费者反映尺码偏大,但整体上能为不同体型的消费者提供合适的选择[^3^]。4. 易于打理: - 全棉材质的T恤虽然容易发皱,但真维斯的产品耐洗耐磨,经过多次清洗仍能保持原有的形态和色彩[^2^]。 - 真维斯T恤的保养相对简单,不需要过于复杂的洗涤要求,适合快节奏生活中追求高效便利的消费者。5. 品牌信任: - 作为一个有着深厚历史背景的品牌,真维斯经历了市场的长期检验,积累了大量忠实消费者[^3^]。 - 消费者普遍反映,真维斯T恤的质量与品牌宣传相符,从而建立了良好的品牌信任度。6. 产品多样: - 除了常规的T恤外,真维斯还提供包括短裤、牛仔裤等在内的多样化产品选择,满足不同场合和季节的需求[^3^]。 - 真维斯不断跟进市场趋势,推出符合当下潮流的新款服饰,满足年轻消费者对时尚的追求。7. 购物便捷: - 在多个电商平台及实体店铺均可轻松购得真维斯T恤,产品搜索、支付和物流等环节都极为便捷[^4^][^5^]。 - 京东等大型购物平台为消费者提供了丰富的真维斯T恤选择,包括但不限于各种颜色、款式和尺码的选择,极大地丰富了消费者的购物体验。总而言之,真维斯T恤以其合理的价格、优质的材料、简约的设计、便捷的购物过程赢得了市场的广泛认可。作为日常穿着的优选,真维斯T恤无疑是值得推荐的高性价比选择。
+1
0
0
1
2024-06-10
ai是一种趋势
产品 AI 泛化,是一种趋势。但在真正拥抱 AI 大模型的产品之外,AI 的应用走出了另一条路。你在电梯间看到的广告,是 AI 生成的,你在户外看见的广告词,是 AI 生成后修改而来的,甚至你在商场逛街,也会看见“AI”前缀的商品宣传。这世界,好像离开 AI 就无法运转。图源:小红书如果说 AI 帮广告从业者解决了海报设计和 Slogan 的工作困难,这还算一件好事,但当一些产品原封不动把“AI”放在产品名前面,我们就该思考,AI 营销是不是真的被滥用了?收手吧,外面全是 AI走在商场里,看到一个按摩椅。商品名字旁赫然写着“AI 压力监测”的产品介绍。微博用户@自信的眉毛 写到“AI 营销化滥用真的挺没意思的”。虽然照片遮住了产品 logo,但产品的特点明显,不难看出这是 OSIM 傲胜的按摩椅。图上的产品为 uLove3 减压养身椅,是 OSIM 在 CES 2023 上发布的产品。据官方介绍,其主打卖点为 AI 压力监测科技,可以用自身的“AI 紧张度测试”技术,为用户提供私人订制按摩程序。听起来很唬人,毕竟任何产品和 AI 产生联系之后,整个形象就开始变得更加立体。用户心里的疑问像金鱼嘴里的气泡,一个个往上冒。“AI 按摩椅,会有机器手臂给我按肩膀吗?”“会治好我的颈椎病吗?”“会知道我疼的部位,看出我内脏不好吗?”......遗憾的是,这些功能它都做不到。此 AI 非彼 AI。我们现在常见的 AI 多指依托于大模型的技术,而在这个按摩椅上所采用的“AI”恐怕只是更智能的解决方案,和当前最流行的 AI 八竿子打不着,让按摩椅用上大模型,实在有些为难人。类似的事情还发生在其它产品上,家用电器是重灾区。家用电器的受众群体,大多不了解 AI 行业。但新闻对于当前 AI 的渲染,却能让他们更加信任这个词语。AI 扫地机器人、AI 冰箱、AI 洗衣机......万万没想到,AI 泛化的速度比想象中还要快。此时我脑海里已经出现多家企业飘在在 AI 风口上的画面,毕竟英伟达市值都已经暴涨超过了苹果。当“智能”无法满足营销的需求在消费的场景中,“AI”用词自然是好的。它能帮助用户联想产品的优势点,然后在销售人员的推动下,促成这一次交易。站在营销的外部视角来看,此处的“AI”命名是被滥用的标志。换作以前,这款产品的介绍应该是“智能压力监测”。只不过,从“智能”到“AI”,营销也在随着时代发展进行转变。在当前环境下,“智能”二字显然已经不能刺激消费者的眼球。如果你把“AI”连续写 30 遍,你会发现你不认识它了。AI 营销泛滥,只会毁了这个词语。就像当初的“量子纠缠”泛滥一样。由于量子纠缠的现象难以用通俗的语言向大众解释,这四个字看起来便“不明觉厉”。任何与量子纠缠产生联系的产品,瞬间就能纠缠住消费者的钱包。有的产品或许只是加上了“量子”前缀,产品功能尚未有多少变化,对消费者无害。有的人却对量子概念肆意炒作,甚至推出“量子读书法”等让人啼笑皆非的产品。2021 年,人民日报评论曾发布一篇文章《别让量子产品“纠缠”上你!科技拒绝嫁接的“伪创新” | 人民锐见》,文章指出量子理论包装营销是蹭热度嫁接的“伪创新”,更呼吁需要对伪科学产品进行整治,大家得认清“伪科学”的真面目。图源:人民日报评论在未真正泛滥前住手好在当前在 AI 的流行趋势下,并没有发生离谱的营销事件。大抵只是套个噱头,并不会对消费者带来伤害。然而消费者并不需要换汤不换药的“欺骗式”营销。把产品名加上 AI 之后,产品却没有实质上的改变。当消费者将产品带回家之后,会产生极大的落差感,这不仅不会增加复购率,甚至还会损害品牌口碑。真正 AI 技术的应用,还需要很长的时间,需要各方的努力,更需要各企业的自律。不可否认的是,商品/产品的 AI 泛化是一种趋势。从手机到笔记本电脑,再到新能源汽车,首先拥抱 AI 大模型的产品,一定程度上给予了用户便利,真正手握 AI 大模型能力的企业也在认真对待 AI 落地的场景,挖掘更多的功能点。在 AI 营销真正泛滥化之前,我们应该提高警惕。
+1
0
0
0
2024-06-09
汽车大排行
今年一季度,汽车行业的日子普遍难过,蔚来一季度财报也印证了这一点。营收层面,一季度蔚来营收99.1亿元,与上一季度以及去年同期相比都有下降,环比下降42.1%,同比下降7.2%。一季度蔚来整车毛利率9.2%,摆脱了低毛利阶段,但是这对于蔚来来说,还不是理想水平。从整车交付量来看,蔚来一季度新车交付30053辆,同比减少3.2%,加上车型切换至2024款,对老车型的终端促销,影响了蔚来的毛利率。不过在刚刚过去的5月,蔚来已经重回2万辆水平。蔚来的市场层面已经出现起色。图源:蔚来官方在财报电话会中,蔚来汽车创始人、董事长、CEO李斌提到,目前5月份的订单已经超过了蔚来的生产能力,对于二季度的交付,蔚来已经重拾信心,二季度交付指引为5.4万辆至5.6万辆,同比增长129.6%至138.1%;营收指引为165.9亿元至171.4亿元,同比增长89.1%至95.3%。当然,不可否认的是,蔚来依然是新势力车企中亏损幅度较大的车企,一季度蔚来净亏损51.85亿元,同比增长9.4%,环比有3.4%的下降。就在最近举行的重庆汽车论坛上,广汽集团董事长曾庆洪在发言中提到,“这么卷下去,没钱赚、没有效益,企业不可以生存,没有企业能亏几百亿。”造车十年,持续亏损,对于亏损百亿,行业里第一个联想到的就是蔚来。但对于蔚来来说,与企业过度的卷导致上百亿亏损不同,蔚来本身对于价格战并不积极,也不是动辄启动裁员来实施降本的车企。只能说,蔚来在持续构筑护城河的路上,并有着非常清晰的发展闭环,同样在花钱这件事上,蔚来的投入也一直高于同行的新势力。图源:蔚来官方在此次财报电话会上,李斌也透露了一些新信息:NIO Power在完成第一笔融资后,不乏独立上市的可能,这意味着,蔚来的换电业务经过前期布局与技术投入,如今已经成熟,加上产业联盟日渐扩张,距离市场化的日子已经越来越近。第三品牌萤火虫预计提前至今年发布,明年上半年交付。据21世纪经济报道的信息,萤火虫首款新车的发布已经从欧洲首发调整至中国首发,并将在今年年底亮相,这一调整也是为了应对国内日趋激烈的市场竞争环境。新品牌新车型向主流市场靠拢,这也是蔚来在前期大量研发和资源投入之后,亟待通过前期研发资源的复用,降低前期大量投入带来的亏损。产品层面,蔚来从ET9开始逐步切换到第三代平台,通过采用更多自研技术提升毛利率,同时电池成本也有降本空间,预计平均毛利率可以达到20%。一直以来,蔚来都保持着每个季度30亿元左右的研发投入,现金储备也已经在一个稳定的水平。图源:蔚来官方蔚来是一家注重长期投入的品牌,这也是即便在市场低谷阶段,蔚来仍然选择加大对新品牌、换电站持续投入的原因,这也让外界对于蔚来的质疑从来没有停止过。今年将是蔚来长期投入转化为市场收获的一年。当然,这其中也存在一定的不可预知性。
+1
0
0
0
2024-06-08
开源Ai
从何时开始,Qwen在海外和全球开源社区中的使用频率和讨论度开始增加?有哪些关键的时间点?林俊旸:在2-3月份,我们发布了Qwen模型的1.5版本,标志着推广工作的重要里程碑。尽管发布恰逢春节前夕,但这个时间最终证明适合开源,我们顺其自然地进行了发布。云栖大会的成功举办和Qwen-72B模型的开源极大增强了团队信心,国内企业和开发者的高度认可促使我们扩大推广。12月访问香港和新加坡时,我们意外发现海外社区对Qwen了解有限,意识到可能处于信息茧房中。开源生态主要由LLAMA模型主导,它最早开源并得到meta支持,社区在其基础上构建了丰富生态。Qwen 1.5开源时,我们提供了多种部署和使用方式,包括Hugging Face、vLLM、llama-cpp和Ollama等,并支持量化等高级功能。我们认识到,开源模型成功不仅在于效果展示,更在于易用性和生态支持。1.5版本发布时,我们评估了基础语言模型的多元能力,发现表现达到可接受水平。这促使我们投入更多精力进行后续训练和优化,提升模型的多元能力和实用性。通过后续训练,我们的模型逐渐被更多海外用户了解,提升了英语及其他语言能力。我们认为让模型易于使用并确保用户体验到效果是推广的关键。目前,除了东南亚语言,还有团队在进行阿拉伯语等中东语言的继续训练。尽管中东语言审查难度大,我们保持乐观态度。随着模型开发和使用增多,Qwen讨论度自然上升,普及是逐步发生的。尽管国内媒体报道可能滞后,Qwen的知名度和使用率正在稳步增长。对于开源大模型来说,社区和开发者最关心的问题是什么呢?特别是零一万物的Yi模型面向全球开源社区时所积累的重要心得和经验是什么?林旅强:性能是模型推广的核心,模型需要在榜单排名或用户感受上展现出强大。开发者最重视还是大模型本身的能力;在推广模型时,开发者的第一印象是来自测评榜单的排名,例如世界知名的LMSYS;但榜单不能完全代表在实际应用场景下的能力,更真实的感受和评价是来自于开发者用户实际的使用过程中。模型让开发者觉得是强大的基础上,我们非常重视开发者体验,这包括Yi选择基于GPT/LLAMA的公开架构以及兼容其生态来提升易用性,并简化开发者上手过程。鉴于训练新版本需要好几个月的时间和有限的团队和算力资源,在版本迭代的过程中优化模型的易用性变得至关重要。当前Yi和Qwen是由中国厂商主导在海外声誉最佳的模型,也跟上述因素有关。除了通过生态位选择和架构设计,让模型易于使用之外,我们重视每个Yi开发者,通过在社区的有效沟通和工作,追求服务质量而非仅仅是用户数量增长,确保开发者的反馈能在一定时间内得到改善和回应,这些细致的工作正是打造优质开发者关系的关键。我们相信开源开发者生态依赖于口碑,国内生态需要更多中立角色,以开发者为中心进行良性竞争。海外开发者更注重体验,无论是使用开源模型还是API,都追求良好体验。目前大模型还属于早期阶段,还是一个增量市场,用户数量都还不多,此外在国产算力适配模型等还有许多工作待完成,这些开源和开发者生态的工作都还在构建基础建设的阶段,这方面的投入需要战略定力。浪潮信息为什么选择走开源的路?做的过程中得到了哪些国内和全球化用户的反馈?李峰:国内AI技术,尤其是大模型的发展,要“一子两用”,既要稳固自身,也要给对手施压。从战略角度来看,大模型的开源是实现“一子两用”的关键一步。国内开源的大模型对国外产生了影响,迫使国际上的AI技术巨头关注国内的开源模型。这种开源开放的做法,对国际闭源的大模型服务和应用带来了冲击,迫使国际上的头部玩家在基础模型上加快创新步伐。骆轶航:上周我们讨论这个话题的时候,尤洋老师马上就出来说,接下来大家最应该关心的事情应该是LLAMA跟进的新的开源模型,能够在多大程度上,跟gpt-4O在性能上,在反应上能够去做对比,他说这个是非常重要的事情。李峰:浪潮信息自2021年9月发布源1.0模型后,持续迭代并提供优质中文数据。2022年,训练效率提升50%,首次实现了千亿规模大模型训练效率53%的突破,有效降低成本。2023年11月,发布业界首个千亿规模免费商用的源2.0版本,推动合作伙伴共赢。我们按月更新模型,并推出了YuanChat工具和与魔搭社区合作提升用户体验。注重研发独立性,避免过度依赖自动代码生成。面对计算资源挑战,开发新算法降低75%带宽需求,保持训练效果。基于源2B模型,研发支持长文本代码的long code版本,超越GitHub代码生成局限,同时鼓励研发创新,促进应用落地。骆轶航:上周我们讨论这个话题的时候,尤洋老师马上就出来说,接下来大家最应该关心的事情应该是LLAMA跟进的新的开源模型,能够在多大程度上,跟gpt-4O在性能上,在反应上能够去做对比,他说这个是非常重要的事情。李峰:从浪潮信息的角度,我们主要是提供基础模型,及大模型相关的训练、推理和微调服务,面向的人群主要是企业用户、应用开发商和社区开发者。个人可使用云端或本地模型,TOB业务则提供易于封装和二次开发的工具,以助企业快速部署模型服务。为简化模型选型,我们通过YuanChat平台实现一键体验多模型,并解决不同框架和芯片适配问题。在不久前的IPF大会上,我们也发布了EPAI,这是一个转专为企业级大模型应用而服务的开发平台,包含数据准备、模型训练、知识检索、应用框架等系一系列工具,也完全支持多元算力和多模算法的高效调度。通俗点说就是,在EPAI上,各类开源模型和框架,都可高效运行,一起去助推“百模”与“千行”的融合。骆轶航:浪潮信息在开源平台上的做法与其他公司有所不同。浪潮信息致力于将开发者和研发人员所需的工具和具体场景解决方案封装成工具包和功能包,以便于开发者更容易地使用和集成。基于这种反馈,我们如何能够让这件事像飞轮一样正向循环起来?李峰:我们提供基础模型、训练、推理和微调服务,面向个人和企业用户。个人可使用云端或本地模型,TOB业务则提供易于封装和二次开发的工具,以助企业快速部署模型服务。为简化模型选型,我们与魔搭合作,通过源chat平台实现一键体验多模型,并解决不同框架和芯片适配问题。与IPF合作的EPAI AI平台进一步优化了框架和芯片适配,通过自研框架使计算资源调用更直接。这些措施让浪潮大模型和各种开源或商业模型在我们的平台上高效运行。企业视角下的开源工作推进骆轶航:李老师在讨论中主要关注的是用户的感受,特别是开源社区开发者的感受以及他们与我们的互动。如果我们没有理解错的话,我们的工作主要是通过工具和大模型的能力去赋能开发者,比如源,比如EPAI。但你们同时也坚持开源开放,比如多元算力、多模算法,再一起携手去为行业落地服务。我首先先确认我的理解是正确的,我们确实是在使用开源社区的资源,这样的飞轮就转起来了。汪东瑶:从客户的视角来看,开源对我们工作的推进至关重要。在开源模型变得普遍之前,我们已经在自行训练模型。实在智能起初专注于RPA,目标是提高数字员工的工作效率。ChatGPT的推出激发了我们训练自己的大型模型,我们计划利用prompt让模型能够调用RPA组件和工具。接口的token限制(最初4096个token)限制了模型理解RPA的能力,我们通过让模型内化RPA和软件操作知识来解决这个问题。自去年2月起,我们组建了团队,成为国内早期自主训练模型的公司之一,经历了从准备语料到SFT和强化学习的挑战。去年7月,我们发布了大模型塔斯,但token限制和软件更新依然是挑战。随着国内开源模型如Qwen的出现,我们得以在现有基础上继续工作。我们的模型最初基于6B结构,而升级到13B则资源消耗巨大,因此我们转而在开源模型基础上进行工作。今年,国内出现了更多优秀的开源模型,例如支持超长文本的kimi,这使我们能够通过prompt直接输入大量内容,使模型能够基于上下文做出正确的选择。这些开源大模型对我们具有重大的实际意义。骆轶航:确实,开源模型对我们来说具有重要的意义。根据我的理解,从去年7月份到8月份之后,你们公司内部在模型开发路径上经历了一个显著的变化。在这个过程中,我想坦率地讨论一下,你们大概参考了多少个开源模型,或者实际上使用了哪些模型。刚才提到,有些大公司或客户会表示他们使用了多家的模型,包括你们的产品。我想知道,你们大概用了多少个开源模型,其中有多少是中国公司开源的,又有多少是全球其他公司开源的。汪东瑶:我们最初使用的是Bloom模型,但Bloom并不支持中文,所以我们需要在中文语料上进行大量的继续训练(continue training)。在13B模型的开发初期,由于13B模型开源较早,我们最早使用的是Lama模型。但后来我们发现,Lama在中文能力方面相对于Qwen模型来说较弱。因此,当我们开始使用13B模型时,我们是基于Qwen的技术框架进行训练的。到了今年4月份,我们正在开发的70B模型是基于deepseek和Qwen模型进行选型和训练的。这就是我们模型开发和选型的一个过程。中国的这些模型在全球市场上与开发者互动的能力是什么?它们真正的优势在哪里?骆轶航:我们正在讨论选择使用哪个模型,以及新一轮大语言模型,尤其是非开源模型,它们是如何在全球范围内与开发者互动的。中国的这些模型在全球市场上与开发者互动的能力是什么?它们真正的优势在哪里?最近,我注意到一位我非常尊敬的大厂大佬在巴黎的会议上发表了演讲。他强调,主要服务中国市场的中文能力是我们的竞争力。然而,我认为,至少我们中的一些人,在全球市场上面对全球开发者和社区时,提供开源模型,中文能力可能并不是我们真正需要强调的能力。我们需要思考,我们的核心优势是什么?我们如何让别人使用我们的模型的最重要能力是什么?汪东瑶:中文能力是我们的一个显著优势,主要因为国内用户构成了我们的核心客户群体。在实际应用中,特别是在生成RPA组件方面,Qwen模型展现出了其代码能力。这在数据分析和其他相关任务中尤其实用。相较于GPT,Qwen在理科领域的表现更佳,具备较强的分析能力,特别适合处理需要逻辑和分析的任务。林旅强:目前市场上模型众多,开发者不会只使用某一家模型,而是会根据其具体的应用场景测试多款模型,再依据测试结果、性价比、模型口碑、社区支持和公司战略综合判断,后续也会随着推陈出新的模型动态调整其模型选用的策略。同时,部分开发者也会考虑模型的独特功能和输出风格,以满足具体需求。广泛测试和深入了解各家头部模型特性对选择合适的模型和调整prompt至关重要。林俊旸:我们专注于模型的差异化,尤其是在function-calling和agent能力上,通过标注数据测试模型。我们的模型无需额外agent即可满足用户需求,并在1.5版本中重点改进了训练方法。尽管面临RLHF挑战,DPO技术帮助我们提升了模型的个性化和优雅性。用户反馈显示,我们的模型在文学创作和翻译方面受到青睐。骆轶航:在早期你们通过强调function和agent功能,尤其是理科相关的功能,来吸引用户。我们想知道这种策略的效果如何?林俊旸:即将增强模型代码能力。面对竞争,我们专注于代码性能提升。新代码模型将基于经验优化,提高产品整体性能。尽管其他模型如llama在coding方面有进步,我们的模型在特定场景下仍需提升数学和推理能力。骆轶航:编码能力不足,以及数学能力不足,可能会影响到模型在多个方面的表现。这包括文字输出和语言输出的质量。林俊旸:在执行简单任务时,很多人认为我们的模型性能远超3.5版本,有时甚至接近4.0版本。然而,也有人认为在某些方面,3.5版本仍然可用,而我们的开源模型可能仍有不足之处。对我们来说,挑战在于找出这些不足的点,并加以改进。实际上,我们并不害怕卷,我们害怕的是找不到问题所在。如果无法识别问题,我们就无法进行有效的优化。骆轶航:我的核心观点是两个竞争力:一个是在coding方面,我认为function call agent以及coding能力是本质上的关键能力。你提到最近一段时间,我们更多地展示了文科方面的能力,比如中英互译,知乎上有人讨论的信达雅翻译。这是否过度依赖了Qwen作为中文领域积累的大语言模型的能力?如果以全球影响力作为衡量标准,那么这种能力可能并不是最本质的东西。林俊旸:我们的主要用户是中文用户,因此我们接触到的案例多,尽管我们支持多语言。我们通过实验确定不同语言数据的贡献,并以此构建多语言模型。我们依靠实验结果而非争论来达成共识,并确保在优化中文能力的同时,不损害英文和其他语言的基本能力。什么样的开源才算是有诚意的开源?骆轶航: 接下来我们讨论开源话题。中国开源社区已经从受益者转变为贡献者,这一变化具有本质意义。自去年以来,中国的大型模型陆续开源,改变了中国在全球开源社区的角色。中国的开源社区在协作方面表现出色,这一点在全球范围内得到了认可。开源的活跃参与者数量并不多,这使得协作变得尤为重要。这也引出了关于中国公司开源彻底性的问题,这成为了衡量中国大模型对全球开源社区贡献的一个重要指标。我们探讨了开源的彻底性,包括语料库的开源。一些公司甚至开源了深度语料库供大家使用,这在推特和其他地方引发了讨论。有人认为中国的开源是最彻底的。我们可以进一步讨论,对于国际社区和全球社区来说,什么样的开源才是真正的、有诚意的开源。同时,作为用户,我们应该考虑什么样的开源是真正有价值的。汪东瑶: Function calling 是我们为 agent 训练的重点功能,但中文语料库的缺乏带来了挑战。我们认为彻底的开源应包括数据和处理方法的分享,这有助于提升模型质量,并在深层次 reasoning 上缩小与 GPT 等模型的差距。数据构造和训练技巧至关重要,早期项目中英文语料更常见,因为中文语料较为缺乏。骆轶航:我们正在讨论一个非常重要的问题:开源的真正含义及其彻底性。作为开源的提供方,我们探讨了开源的评判标准,以及我们如何进行开源,或者至少从目前收到的反馈来看,我们看到了哪些情况。
+1
0
0
0
2024-06-07
<
上一页
1
...
9
10
11
12
13
14
...
64
下一页
>
转至
页
GO
991
关注
265
粉丝
社区达人榜
查看更多
1
哈687
2
斑鸠
3
数码和汽车分享
4
多多神器
5
可爱的小cherry
关注数量超出限制,
请先删除部分内容再尝试