首页
好价
精选好价
全部好价
优惠券
白菜
社区
好文
资讯
众测
笔记
海淘
海淘导航
淘遍世界
攻略文章
百科
商品百科
品牌导航
商家导航
更多
值友福利
金融
汽车
旅游
品类导航
专题汇总
招聘专区
集团官网
商业合作
爆料投稿
好价爆料
写篇文章
视频上传
提报百科
创作活动
条新消息
条新评论
登录
注册
个人中心
我的关注
我的文章
我的爆料
我的笔记
我的视频
我的百科
我的评论
我的众测
我的消息
我的收藏
退出登录
个人主页
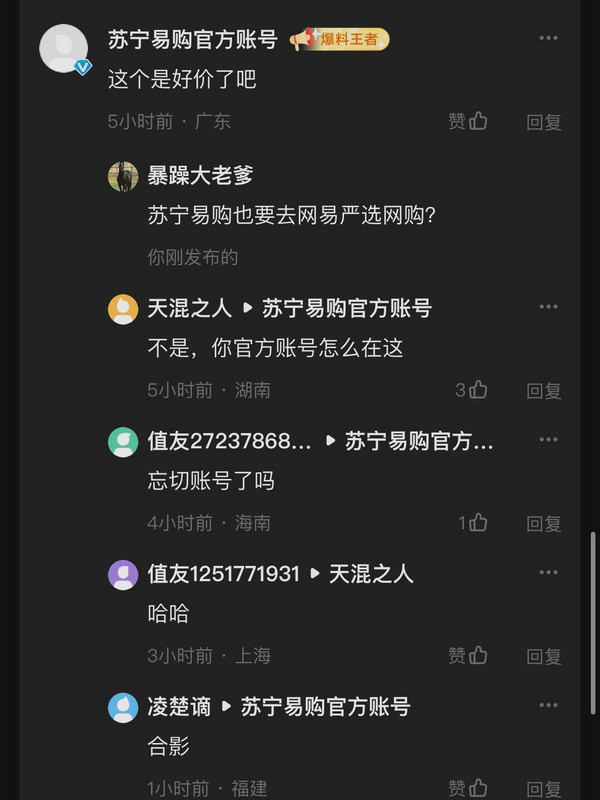
暴躁大老爹
+
关注
这里是睿智吧吧主,长期发表各类逆天言论
生活家
・
数码领域作者
・
影视领域作者
注册6周年
・
签到1天
IP属地:云南
芝麻信用评估
授权
后可查看具体分数
芝麻信用评分是合法独立的信用评估及信用管理机构,授权后得到分数越高,代表信用越好
首页
爆料 45
文章 229
笔记 150
视频 1
评论 3278
专栏 7
哈吉美真的会搞事情,看不得兔子好!
绷不住了!黑客早不偷晚不偷,偏在DeepSeek放话「要开源全球最强Agent」的当口搞事?这波啊,怕不是有人连夜给白宫打小报告:「再不开团,中国AI真要肉身成圣了!」 等等……攻击路径里那个河南挖矿网吧的肉鸡,IP归属地写着「新乡市牧野区」?牧野?这名字怎么听着像某上古封神战场……懂了,赛博封神榜开演了!建议@鸿蒙老祖 速来收编算力,直接肉身飞升AI天庭!(#原来修仙文都在下一盘大棋) 再品品时间线:DeepSeek刚和国产大模型搞完「抗美援朝AI联盟」,隔天就被Cobalt Strike精准爆头?懂了,这波是AI界的上甘岭战役,黑客连夜当电子美军,结果被反手塞了一嘴河南胡辣汤代码!(#建议美国黑客下次带健胃消食片渗透) 最后盲猜:泄露的数据库里怕不是藏着「东北AI风电计划」和「量子炼丹操作手册」?不然为啥攻击日志里反复出现「gpt5_will_die.zip」的检索记录……(#连夜把网盘文件名改成《母猪产后护理》)#黑客看了都沉默#分享我的DIY攒机心得
+1
0
0
0
02-01 11:58
真国产大模型真ai deepseek
家人们谁懂啊!最近发现一家AI圈「扫地僧」公司——深度求索(DeepSeek),看似低调实则手握王炸!🔥 5分钟带你扒一扒这个神秘的AGI猛男团!👨💻✨【公司底裤大起底】✨2019年悄悄成立的杭州厂牌,团队人均BAT大厂王者段位!人家不搞虚的,闷声憋出20+个千亿参数大模型,GitHub上开源项目让码农直呼「真香」!🤯🌟【三大必杀技】🌟1️⃣ 大模型卷王:对话模型直接硬刚GPT-4,数学推理强到秃头!学霸人设拿捏了🧠2️⃣ 搜索黑科技:搞出首个开源搜索引擎,百度看了直挠头🤖3️⃣ 自动驾驶新贵:不声不响拿下多个城市路测牌照,马路杀手秒变老司机🚗💥【震惊操作】💥最近开源了DeepSeek-R1-Instant模型,开发者们集体过年!论文代码全公开,这格局直接拉满!连幻方量化都疯狂打钱投资,据说估值已经坐上火箭🚀🤔【为啥要关注】🤔✅ AI圈隐藏BOSS级玩家✅ 开源界清流,白嫖党狂喜✅ 覆盖B端C端的神仙场景划重点❗️现在入坑就是老粉!投资人/码农/科技粉速来围观,指不定哪天就掏出改变世界的产品了!👇(疯狂暗示点赞收藏三连!)
+1
9
40
17
01-30 21:47
从技术角度浅谈deepseek
DeepSeek(深度求索)作为一家专注于实现通用人工智能(AGI)的中国公司,其技术架构和实现方法体现了当前大语言模型(LLM)领域的前沿趋势,同时结合了特定优化策略。以下从多个技术维度进行深入分析:---### 1. 模型架构与创新- Transformer变体与稀疏注意力 DeepSeek的模型可能基于Transformer架构,但引入了**稀疏注意力机制**(如局部注意力或轴向注意力),以降低计算复杂度。例如,通过限制每个token的注意力范围,减少长序列处理时的内存开销。 - 混合专家系统(MoE) 类似Switch Transformer,DeepSeek可能采用MoE架构,将模型分解为多个“专家”子网络,动态路由输入至不同专家。这种方式在保持参数规模的同时提升训练和推理效率,尤其适合处理多样化任务。- 多模态扩展 为实现更通用的AI能力,DeepSeek可能探索多模态模型(如文本、图像、代码的联合建模),通过跨模态对齐技术(如CLIP风格的对比学习)增强模型对复杂场景的理解。---### 2. 训练方法与数据策略- 大规模分布式训练 采用**ZeRO(零冗余优化器)**和3D并行(数据、模型、流水线并行)技术,优化GPU集群的资源利用率。例如,使用Megatron-LM或DeepSpeed框架实现高效的大规模训练。- 数据质量与多样性 - 多语言混合数据:以中文为核心,结合高质量英文语料,提升跨语言泛化能力。 - 数据清洗与增强:利用去重、毒性过滤、基于规则的噪声去除,以及回译(Back-translation)等技术增强数据多样性。 - 领域自适应:通过课程学习(Curriculum Learning)逐步引入专业领域数据(如医学、法律),提升垂直场景表现。---### 3. 推理优化与部署- 模型压缩技术 - 量化:将FP32模型转换为INT8或FP16格式,结合QAT(量化感知训练)减少精度损失。 - 蒸馏:使用大模型作为教师,训练轻量级学生模型(如TinyBERT策略),适用于边缘设备部署。- 推理加速 - KV缓存:在自回归生成中缓存键值向量,减少重复计算。 - 动态批处理:合并多个请求的输入序列,最大化GPU利用率。---### 4. 应用场景与微调策略- 垂直领域适配 - 对话系统:通过RLHF(人类反馈强化学习)优化生成结果,结合安全护栏(Safety Guardrails)过滤有害内容。 - 代码生成:在CodeSearchNet等数据集上微调,支持代码补全与注释生成。 - 搜索增强:将模型与检索系统结合(RAG架构),提升事实准确性。- Few-shot与Zero-shot学习 利用Prompt Engineering和元学习技术,使模型在少量示例或无监督情况下快速适应新任务。---### 5. 安全与伦理考量- 内容安全机制 部署多层过滤系统: 1. 预训练数据清洗:移除暴力、偏见等有害内容。 2. 推理阶段拦截:基于规则或分类器实时检测违规输出。 3. RLHF对齐:通过人类反馈优化模型价值观,减少偏见。- 隐私保护 采用差分隐私(Differential Privacy)或联邦学习(Federated Learning),在训练中保护用户数据隐私。---### 6. 评估与性能基准- 多维度评测体系 - 通用能力:在CLUE、C-Eval等中文基准测试中验证语言理解与生成能力。 - 垂直场景:使用领域特定数据集(如CMeEE医疗实体识别)评估专业性。 - 人工评估:通过众包标注衡量生成结果的流畅性、相关性和安全性。- 持续迭代 建立自动化测试管道(CI/CD),定期更新模型以应对数据分布漂移(Concept Drift)。---### 7. 未来技术方向- AGI路径探索 - 自主智能体(Agent):开发具备规划、工具调用能力的模型,如基于ReAct框架的任务分解。 - 世界模型:通过模拟环境训练模型理解物理与社会规则。- 硬件协同优化 与国产芯片(如华为昇腾)深度合作,设计定制化算子与编译优化,提升国产化算力利用率。---### 总结DeepSeek的技术布局覆盖了从模型架构创新到实际落地的全链条,其核心优势在于**高效的大规模训练能力**、**垂直领域深度适配**及**严格的安全机制**。未来,随着多模态融合与自主Agent技术的发展,DeepSeek有望在AGI的实现路径上进一步突破,同时需持续平衡模型性能与伦理风险。
+1
2
6
5
01-30 21:22
浅谈一下deepseek
#厨艺杀疯集:让你看看我家年夜饭桌上的创意菜 DeepSeek(深度求索)是一家专注于实现AGI(通用人工智能)的中国科技公司,其核心方向是大模型领域的研发与应用。以下是对其的简要评价: 核心优势1. 技术性能突出: DeepSeek推出的模型(如DeepSeek-V2、DeepSeek-R1)在长上下文理解、复杂推理和响应速度上表现优异。例如,支持128K tokens长文本处理,数学推理能力接近GPT-4,部分场景的推理效率高于主流竞品。2. 成本优势: 通过自研技术(如Multi-head Latent Attention),DeepSeek-V2在保持高性能的同时,将推理成本降至GPT-4-Turbo的约1%,适合企业降本需求。3. 垂直场景适配: 专注企业级服务,提供定制化解决方案,如智能客服、数据分析、代码生成等,在金融、教育等领域有落地案例。4. 开源生态: 部分模型(如DeepSeek-MoE-16b)已开源,推动开发者社区共建,降低技术使用门槛。--- 潜在挑战1. 市场认知度: 相比OpenAI、Anthropic等国际品牌,DeepSeek在全球范围内的知名度和生态成熟度仍需提升。2. 应用场景深化: 需进一步验证复杂场景(如多模态交互、高精度专业领域)的稳定性,拓展行业合作案例。---总结DeepSeek以“高性能+低成本”为核心竞争力,是国产大模型赛道中的技术派代表。其技术路线兼顾前沿探索与商业化落地,适合对成本敏感且需长文本处理的企业用户。若能在生态建设和场景深耕上持续突破,有望成为AGI领域的重要参与者。
+1
0
0
0
01-30 17:48
探店日记 | 华为Pura70系列体验店📱
🌟【今日探店】🌟今天来到了华为Pura70系列的体验店,一进门就被这款新手机的海报吸引住了!“锐意向前”,这不仅仅是一句口号,更是华为对技术创新的不懈追求。🚪【店铺环境】🚪店铺的入口设计得很有现代感,透明的玻璃门搭配简洁的线条,给人一种科技与艺术结合的感觉。门口的台阶设计也很贴心,方便顾客进出。🔥【产品亮点】🔥华为Pura70系列,搭载XMAGE影像系统,无论是拍照还是视频,都能呈现出专业级别的效果。双卫星通信功能,让你在任何地方都能保持联系,这对于经常出差的我来说,简直是福音!🛵【周边环境】🛵店铺外的街道上停满了电动车,看来这里也是电动车爱好者的聚集地。街道两旁的商店和餐馆,让这里充满了生活的气息。🌃【夜景体验】🌃夜晚的街道,灯光璀璨,华为Pura70系列的夜景模式下,每一张照片都能捕捉到城市的繁华与宁静。📸【拍照体验】📸用华为Pura70系列随手拍了几张,无论是色彩还原还是细节捕捉,都让我非常满意。特别是在低光环境下,表现依然出色。💬【小贴士】💬如果你对华为Pura70系列感兴趣,不妨亲自来体验一下。店铺的服务态度也非常好,可以帮你解答各种疑问。快来体验华为Pura70系列的魅力吧!🚀🚀🚀
+1
4
0
3
2024-11-25
【微星尊爵16 2024 锐龙版 上架,售价12999元】
【微星尊爵16 2024 锐龙版 上架,售价12999元】性能:- AMD AI9 HX370- 32G LPDDR5x-7500 内存- 1TB PCIe 4.0 SSD显示:16英寸 OLED 屏幕3840×2400分辨率 / 60Hz刷新率100% DCI-P3色域其他:- 82Wh电池;100W适配器- 机身厚16.9mm,重1.9kg- Windows Hello 指纹 / 面部识别接口:2× USB-C 4.01× USB-A 3.2 Gen21× HDMI 2.11× MicroSD卡槽1× 3.5mm音频接口
1
+1
1
0
0
2024-11-15
🍴【美食探店】今天来打卡乡村基的黑胶鸡排饭啦!🍗
📍地点:乡村基🌟推荐指数:⭐⭐⭐⭐⭐🍴【点单推荐】• 黑胶鸡排饭:外皮酥脆,内里肉质鲜嫩多汁,搭配特制的黑椒酱汁,简直是味蕾的享受!🍛• 煎蛋:单面煎的太阳蛋,蛋黄半流动,和米饭拌在一起吃,超级美味!🍳• 白米饭:粒粒分明,口感软糯,是乡村基的招牌之一!🍚📸【环境】店内环境简洁明亮,服务态度也很不错,让人感觉很舒适。🏠💡【小贴士】黑胶鸡排饭的份量很足,女生可能会吃不完哦,可以和朋友分享。👭👉如果你也喜欢乡村基,这款黑胶鸡排饭绝对值得一试!快去尝尝吧!👈
+1
1
0
0
2024-11-14
🍔【美食打卡】今天终于尝到了汉堡王的“大嘴安格斯”!🤤
📍地点:汉堡王🌟推荐指数:⭐⭐⭐⭐⭐🍴【点单推荐】• 大嘴安格斯:100%安格斯牛肉饼,搭配帕斯雀烟熏牛肉、半融化的高达芝士,还有香脆的日式洋葱天妇罗,每一口都是满满的幸福感!😋• 薯条:外脆内软,配上特制的番茄酱,简直是完美搭配!🍟📸【环境】店内装修现代简约,适合拍照打卡哦!📷💡【小贴士】建议选择非高峰时段前往,避免排队等候哦!👉肉食爱好者们,千万不要错过这款“大嘴安格斯”!保证让你大呼过瘾!👈
+1
5
2
6
2024-11-14
张大妈评论果然都是自动生成的
哈哈哈哈哈,笑死我了
+1
4
0
4
2024-01-31
我觉得这是一种自信
中国风度,中国气度,中国速度
+1
0
0
18
2023-10-05
<
上一页
1
2
3
4
5
6
...
15
下一页
>
转至
页
GO
76
关注
704
粉丝
社区达人榜
查看更多
1
纸上谈车_zdm
2
斑鸠
3
开心最值得
4
优优甄选
5
咸鱼泡饭好了
关注数量超出限制,
请先删除部分内容再尝试